
12月4日-5日,由清华大学人工智能国际治理研究院主办的2021人工智能合作与治理国际论坛在清华大学举行。在以“人工智能技术前沿与治理”为主题的论坛中,中国工程院院士、北京大学信息科学技术学院院长、鹏城实验室主任高文分享了人工智能2.0的战略、战术和安全问题。
高文介绍,中国人工智能发展规划是从2015年7月份开始,2017年7月发布的《中国人工智能发展规划》就是人工智能2.0正式的说法,提出2020年达到与世界先进水平同步,2025年部分领先,2030年总体领先。
他在演讲中分享到,通过和欧洲、美国等国家在人才数量、研究水平、开发能力、应用场景、数据、硬件等方面的比较分析,中国人工智能发展的水平,存在“四长四短”。即在人工智能发展政策支持、海量数据资源、具备丰富的应用场景,以及青年人才数量和成长速度等方面具有优势;在人工智能的基础理论和算法、高端芯片和关键器件、开源开放平台,以及高水平人才数量等方面则存在短板。
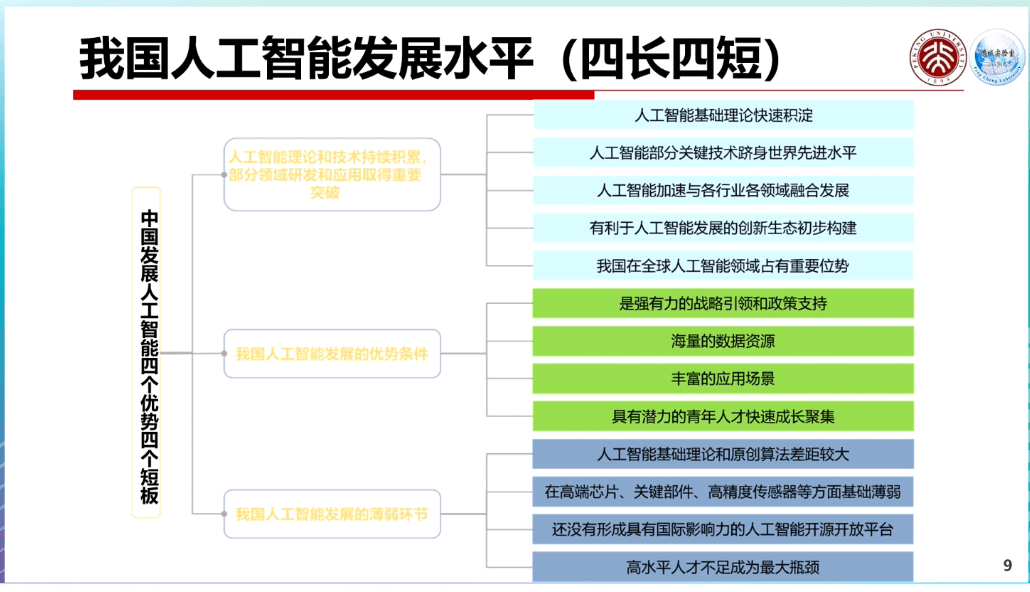
“在短的方面倾注一些资源,尽快补齐短板,使得长板更长,短板不短,发展人工智能是这样的战略。”高文称。
具体战术应该怎么做?高文表示,人工智能2.0需要重点考虑两个方面。一是做可解释的机器学习+推理,在小数据、可解释模型的研究主线上,解决人工智能的问题。第二个技术路线是靠深度神经网络,利用仿生系统+AI大算力解决问题。
高文认为,第二条路线会是人工智能现阶段发展的主要推动方式,而靠大数据、大算力来做人工智能,关键需要有基础设施平台,需要有非常大的算力。
据了解,高文在2018年主导成立的鹏城实验室在去年就推出了算力高达1000P FLOPS(每秒计算速度达10的18次方)的鹏城云脑2,做到节点之间延迟低、带宽非常宽,从而使得机器训练的时候,大数据很容易传输,效率可以发挥到极致。鹏城云脑2在连续三届世界超算打榜中吞吐性能方面绝对领先,在世界人工智能算力500排行中也连续两次获得第一。
高文介绍称,用这台机器已经训练了若干个大模型,比如基于自然语言处理的大模型鹏程·盘古,基于计算机视觉、跨模态的大模型鹏程·大圣,基于多对多模式的模型鹏程·通言,以及面向生物制药、基因制药的大模型鹏程·神农等。他表示,鹏程系列模型基本都支持开源开放,通过启智开源开放平台提供开源开放的程序,可以下载进行使用。
但由此也会带来新的问题。“如果基于类脑和大数据、大算力的技术路线,很显然有一个坎儿必须要迈过去,就是数据安全和隐私问题。”高文表示,这需要从两个层面考虑,数据和隐私安全问题、人工智能伦理问题。
对于数据隐私安全问题,高文认为,人工智能应用离不开数据,在隐私保护和数据挖掘之间,需要找到比较好的平衡点。
这个平衡点在哪里?高文分享了一种隐私和数据安全保护的手段——把数据模型和应用分成三层,每层用接口隔离开(数据到模型之间通过数据程序接口隔离,模型到应用通过应用程序接口隔离),这样就有可能去规范,对数据进行保护。
比如在数据和模型之间,鹏城实验室设计的防水堡技术就可以实现对数据只分享价值,而不分享数据的可信计算环境,做到数据可用不可见,使得数据拥有方或数据本身得到很好的保护。
关于伦理问题,高文介绍了其牵头的研发成果,认为强人工智能安全风险的来源主要有三个:一是模型的不可解释性,二是算法和硬件的不可靠性,三是自主意识的不可控性。强人工智能进化到一定程度就有自主意识,这些可能是不可控的,也会带来一些安全风险。
高文就此也提出了预防和解决的办法。一是要完善理论基础验证,实现模型可解释性,可解释了就知道哪里有风险,怎么样预防;其次要对人工智能底层价值取向要严格进行控制,预防人为造成的人工智能安全问题,对人工智能进行动机选择,为人工智能获取人类价值观提供一些支撑。
他还表示,对于人工智能伦理问题的探索才刚刚起步,只有广泛的国际合作才可能更好的应对风险。同时,教育也是重要环节,培养对这个领域有更多见解的人才,才有可能把这些问题解决好。来源:搜狐科技
 金大立免费服务热线
金大立免费服务热线 地址:成都彭州市工业开发区天彭镇旌旗西路419号
地址:成都彭州市工业开发区天彭镇旌旗西路419号二维码
